FILTRADO ADAPTATIVO
![]()
FILTRADO ADAPTATIVO
![]()
Generalmente, las señales con las que trabajamos no son estacionarias, por ello, el filtrado de Wiener no resulta apropiado en estas situaciones. Una forma de solventar este problema consiste en operar con el proceso en bloques, sobre intervalos en los cuales el proceso pueda ser considerado aproximadamente estacionario. Pero esta técnica presenta limitaciones en su efectividad por varias causas. En primer lugar, para procesos con gran velocidad de variación, el intervalo sobre el que podemos considerar estacionariedad va a ser demasiado pequeño para conseguir una resolución apropiada. Por otra parte, esta técnica no puede incorporar fácilmente cambios en los intervalos de análisis. Por último, y más importante, esta solución impone un modelo incorrecto para los datos, es decir, considera estacionariedad donde no la hay. Por tanto, para obtener unos resultados más precisos, debemos comenzar nuestro estudio bajo el supuesto de no estacionariedad.
Recordamos que para el caso del filtro Wiener FIR, con coeficientes w, la estimación de la señal en sentido de mínimo error cuadrático medio es
![]()
Con x(n) y d(n) procesos estacionarios en sentido amplio, la solución de Wiener resulta wopt = R-1 p. Pero ahora los procesos con los que trabajamos no son estacionarios, y los coeficientes del filtro que minimizan E{|e(n)|2} dependen de n:
![]()
donde wk(n) es el coeficiente k-ésimo en el instante n. De esta forma, la salida del filtro y(n) se puede expresar como
y(n) = wH(n) x(n)
donde
wn = [ w0(n) w1(n) ... wp-1(n)]T
x(n) = [ x(n) x(n-1) ... x(n-p+1)]T
El diseño de un filtro adaptativo (tiempo variante) es mucho más complicado que el de un filtro de Wiener (tiempo invariante), ya que, para cada instante de tiempo n, se ha de encontrar un conjunto de coeficientes óptimos, wk(n) para k = 0, 1, ..., p-1. Pero podemos simplificar el problema considerando una actualización de los pesos del filtro de la forma
w(n+1)= w(n) + Dwn
donde Dwn es un factor de corrección que se aplica a los coeficientes w(n) en el instante n para obtener el nuevo conjunto de coeficientes w(n+1) en el instante n+1. Esta ecuación de actualización es la base de los algoritmos adaptativos, y el diseño de cada filtro adaptativo requiere definir este factor Dwn.
Incluso para procesos estacionarios, en ocasiones resulta más apropiado implementar un filtro variante en el tiempo por varias razones: primero, si el orden del filtro p es muy elevado, puede ser muy complicado resolver las ecuaciones de Wiener-Hopt directamente; segundo, si la matriz R está mal condicionada, las ecuaciones a resolver son muy sensibles a errores de redondeo y efectos de precisión finita; por último, para obtener la solución de Wiener es necesario conocer la autocorrelación rx(k) y la correlación cruzada rdx(k). Aunque se pueden estimar a partir de medidas de los procesos con promedios temporales
![]()
![]()
se produce un retardo de p muestras. Y, en un entorno cambiante, estos promedios han de actualizarse continuamente.
La clave de un filtro adaptativo se basa en un algoritmo que define cómo se ha de aplicar la corrección Dwn. Es evidente que estas correcciones deben reducir el error cuadrático medio. De hecho, independientemente del algoritmo utilizado, se ha de cumplir:
![]()
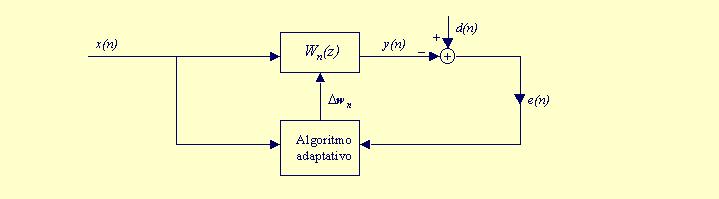
El algoritmo adaptativo debe disponer del error e(n) para actualizar los coeficientes, ya que e(n) permite definir las prestaciones del filtro y determinar la forma en que han de modificarse dichos coeficientes.
La eficiencia de un filtro adaptativo depende de una serie de factores, como el tipo de filtro (IIR o FIR), la estructura del mismo (forma directa, paralela, lattice, ...), y la forma en que se define la medida de prestaciones (error cuadrático medio, mínimo error cuadrático, ...).
Nuestro estudio se va a centrar en el filtro FIR por varias razones:
Hay tres conceptos principales en la medida de las prestaciones de un algoritmo adaptativo:
Vamos a comenzar desarrollando el método de máxima pendiente, un algoritmo de búsqueda del gradiente. Este algoritmo exige el conocimiento de la estadística, no requiere inversión de matrices (ventaja respecto al método de Wiener), es sensible a la dispersión de autovalores y permite incorporar fácilmente cambios en la estadística.
Posteriormente veremos el algoritmo LMS, mucho más fácil de implementar que el anterior y, aunque realiza una estimación del gradiente muy grosera (se estima de forma instantánea en una sola iteración), resulta un método muy robusto.
Por útlimo, estudiaremos algunos variantes del LMS, como el LMS normalizado, que independiza la convergencia del filtro de la potencia de la señal de entrada, el LMS con factor de pérdidas (leaky), importante en casos de matrices mal condicionadas, o los algoritmos signados, que suponen un gran ahorro computacional y, por ello, son ampliamente utilizados en aplicaciones de tiempo real.
![]()