Algoritmo de Máxima Pendiente
![]()
Algoritmo de Máxima Pendiente
(Steepest - Descent)
![]()
Este método realiza una búsqueda de la solución de Wiener moviéndose por la superficie de error en el sentido negativo del gradiente. Procede de la siguiente manera:
Las correcciones que sucesivamente se aplican a los coeficientes del filtro en la dirección negativa del gradiente conducen al punto de mínimo error cuadrático medio, donde el vector de pesos obtiene su valor óptimo wopt.
Denotemos Ñx(n) como el vector gradiente en el instante n. La actualización de los pesos se puede realizar mediante la relación
w(n+1) = w(n) +(1/2) m [-Ñx(n)]
donde m (el tamaño del paso de adaptación) es una constante positiva real. El factor 1/2 es utilizado para simplificar un 2 procedente del gradiente. Y el vector gradiente resulta:
Ñx(n) = -2 p + 2 R w(n)
donde, como sabemos,
x(n) = rd2(0) - wH(n)p - pH w(n) +wH(n)R w(n)
R = E[x(n) xH(n)]
p = E[x(n) d*(n)]
Y la ecuación de actualización de los pesos queda
|
w(n+1) = w(n) + m [ p - R w(n)] , n = 0, 1, 2, ... |
Expresión que también puede ser escrita como
|
w(n+1) = w(n) + m E[ x(n) e*(n)] , n = 0, 1, 2, ... |
ya que Ñx(n) = -2 E[ x(n) e*(n)].
Debemos observar que si w(n) es la solución de las ecuaciones de Wiener-Hopf, es decir, w(n) es wopt = R-1 p, el término de corrección es cero y w(n+1) = w(n); por tanto, también se anula E[ x(n) e*(n)], y se cumple la condición de ortogonalidad entre datos y error en el punto óptimo de trabajo.
Vamos a estudiar ahora la estabilidad del algoritmo.
Podemos interpretar el método Steepest Descent según el siguiente modelo:
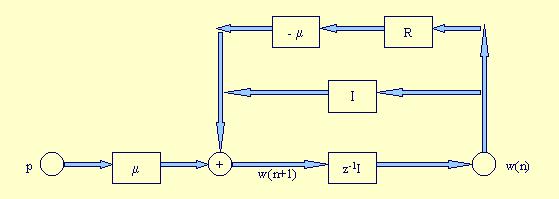
Puesto que hay una realimentación, existe la posibilidad de que el sistema sea inestable. Según el diagrama, la estabilidad del algoritmo depende de dos factores: el paso de adaptación m y la matriz de correlación R, ya que estos dos parámetros controlan la función de transferencia del lazo de realimentación. Para determinar la condición de estabilidad, vamos a examinar los modos naturales del algoritmo. En particular, utilizaremos la representación de la matriz R en términos de sus autovalores y autovectores para definir una versión transformada del vector de pesos.
Definimos el vector c(n) que determina el error entre los pesos (diferencia entre el valor actual de los coeficientes y el valor óptimo):
c(n) = w(n) - wopt
Sustituyendo, en la ecuación de actualización de los coeficientes, p por R wopt y aplicando la nueva transformación
c(n+1) = (I - mR) c(n)
donde I es la matriz identidad. Esta ecuación representa el modelo siguiente, en el que se enfatiza el hecho de que la estabilidad depende únicamente de m y R.
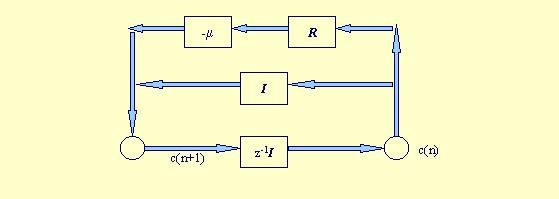
Podemos expresar la matriz de autocorrelación en función de la matriz de autovectores, Q y la matriz diagonal de autovalores L como R = Q LQH.
Sustituyendo en la expresión de c(n+1) obtenemos
c(n+1) = (I - mQ LQH) c(n)
Ahora multiplicamos ambos lados por QH y aplicamos la propiedad QH = Q -1
QHc(n+1) = (I - mL)QHc(n)
Y definimos un nuevo conjunto de coordenadas
v(n) = QHc(n) = QH [w(n) - wopt]
de manera que podemos simplificar
v(n+1) = (I - mL)v(n)
El valor inicial de v(0) es QH [w(0) - wopt], y suponiendo que al inicio del algoritmo, el vector w(0) se encuentra inicializado al vector nulo, tenemos
v(0) = - QH wopt
El k-ésimo modo natural del algoritmo de máxima pendiente es
vk(n+1) = (1- m lk ) vk(n) ; k = 1, 2, ..., p
donde lk es el k-ésimo autovalor de la matriz de correlación R. Esta ecuación representa la versión escalar del modelo anterior, y puede ser visualizada así
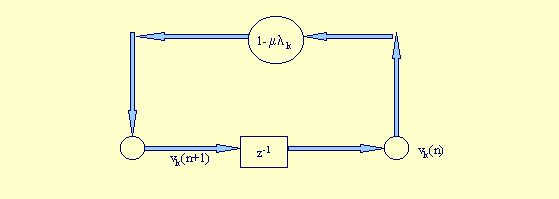
Suponiendo que vk(n) tiene un valor inicial vk(0), podemos expresar la anterior ecuación de la forma
vk(n) = (1- m lk ) nvk(0) ; k = 1, 2, ..., p
Según esta serie geométrica, la razón, 1- m lk, debe ser inferior a 1 para todo valor de k si queremos garantizar la convergencia o estabilidad. Por tanto,
-1 < 1- m lk< 1
De esta manera, al crecer el número de iteraciones, n, los modos naturales decrecen en valor y tienden a cero cuando n tiende a infinito. Esto es equivalente a decir que el vector de pesos w(n) tiende a wopt cuando n tiende a infinito.
Puesto que los autovalores de la matriz de autocorrelación R son reales y positivos, la condición necesaria y suficiente para la estabilidad del algoritmo es
![]()
donde lmax es el autovalor de máximo valor de la matriz R.
Podemos definir una constante de tiempo tk, que indique el momento en que el modo k-ésimo decae a 1/e de su valor inicial, así
![]()
La constante de tiempo para dicho modo es
![]()
Si m es lo suficientemente pequeño para considerar que mlk << 1, la constante de tiempo puede aproximarse por
![]()
Vamos a obtener ahora la evolución del vector de pesos w(n).
A partir de la expresión v(n) = QHc(n) = QH [w(n) - wopt], si multiplicamos ambos términos por Q, llegamos a
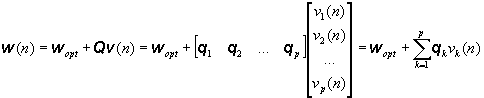
donde los qi son los autovectores asociados a los autovalores li, y vk(n) es el modo natural k-ésimo definido anteriormente como
vk(n) = (1- m lk ) nvk(0)
Si sustituimos esta expresión de vk(n), obtenemos, para el coeficiente i:
![]()
con wiopt el coeficiente i-ésimo del vector óptimo de pesos y qik el elemento i-ésimo del autovector qk. Esta ecuación nos indica que la convergencia de cada peso depende de todos los autovalores.
Podemos definir una constante de tiempo global, t, para representar el tiempo que tarda el anterior sumatorio en decaer a 1/e de su valor inicial. Esta constante no puede ser expresada, a priori, de manera sencilla, pero puede acotarse considerando:
De esta manera, tenemos
![]()
Podemos encontrar una expresión más sencilla, si consideramos t como el tiempo que tarda el modo más lento en decaer a 1/e de su valor inicial
![]()
La constante m está acotada por el valor 2 / lmax, así que podemos expresar
![]()
con 0 < a <1. Y en términos de a, la constante de tiempo es
![]()
donde c = lmax / lmin representa la dispersión de autovalores.
Para finalizar, estudiaremos el comportamiento del error cuadrático medio.
Partiremos de la expresión del error cuadrático medio:
![]()
y sustituimos la expresión de vk(n)
![]()
Si hemos elegido m de forma que satisfaga la condición de convergencia, el sumatorio tenderá a cero al tender n a infinito,
![]()
Si representamos x respecto al número de iteraciones n, obtenemos una gráfica denomina curva de aprendizaje. Esta curva de aprendizaje consiste en una suma de exponenciales, cada una de las cuales corresponde a un modo natural del algoritmo. En general, el número de modos naturales es igual al número de pesos del filtro. Desde el valor inicial x(0) hasta que decae al valor mínimo xmin, la exponencial decae, para el modo natural k-ésimo, con una constante de tiempo
![]()
que para valores pequeños de m puede aproximarse por
![]()
Observamos el efecto de m en la convergencia tk,mse. m debe elegirse de forma que cumpla la condición de estabilidad, pero este valor limita la velocidad de convergencia del algoritmo.
![]()
1.- Predicción de ruido blanco con el algoritmo Steepest-Descent
2.- Diseño de predictor forward de dos coeficientes
![]()
![]()