![]()
Ejemplo 1.- Filtrado LMS.
Consideremos un proceso AR(2) generado según la ecuación
x(n) = v(n) + 1.2728 x(n-1) - 0.81 x(n-2)
donde v(n) es ruido blanco gaussiano de varianza unidad.
El predictor lineal causal óptimo para x(n) viene dado por la ecuación
![]()
Para diseñar este predictor (es decir, para saber que los coeficientes óptimos del predictor son 1.2728 y -0.81), se ha de conocer la secuencia de autocorrelación de x(n). Por tanto, vamos a considerar un predictor lineal adaptativo de la forma
![]()
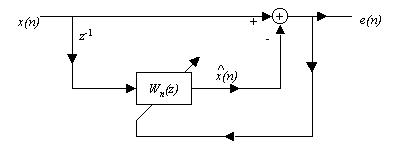
donde los coeficientes se actualizan de la siguiente manera:
wk(n+1) = wk(n) + m x(n-k) e*(n)
Si el valor del paso de convergencia m es suficientemente pequeño, los coeficientes w1(n) y w2(n) convergerán en media a sus valores óptimos, 1.2728 y -0.81, respectivamente. El error de predicción es
![]()
Por consiguiente, cuando w1(n) = 1.2728 y w2(n) = -0.81, el error pasa a ser v(n), y el mínimo error ecuadrático medio es
x
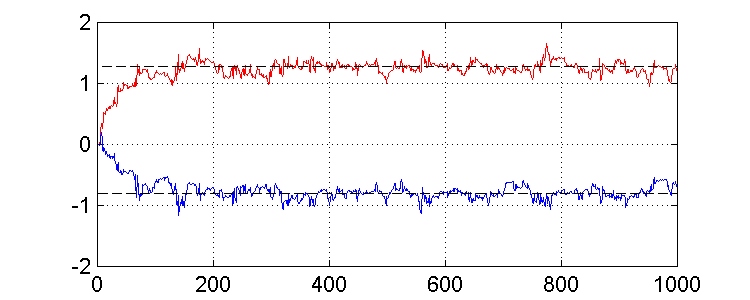
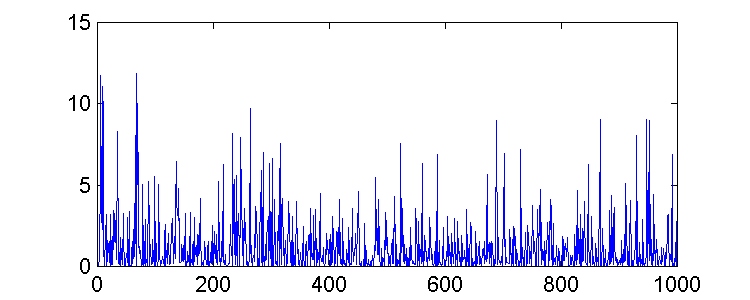
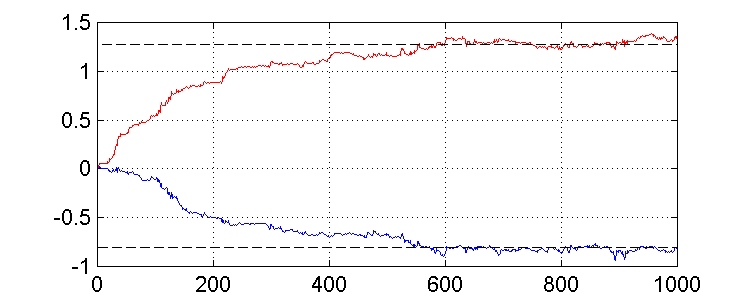
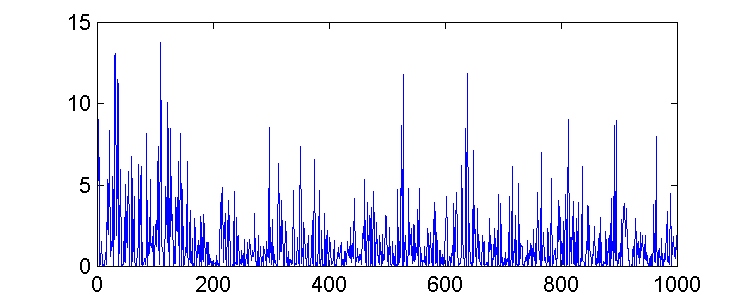
min = sv2 = 1pero, aunque podríamos esperar que el error cuadrático medio convergiera a xmin según el vector de pesos converge a los valores óptimos, esto no ocurre así. Existe una gran variación en los valores del error, como podemos observar en las gráficas.
Comenzamos el algoritmo con un vector de pesos inicializado a cero ( w(0) = 0 ), y consideramos dos valores diferentes de m (0.02 y 0.004).
![]()