
Diagrama de bloques
Principios básicos
Diccionario de unidades acústicas
Módulo de análisis lingüístico
Módulo de síntesis
Generador de prosodia
El proceso de conversión texto-voz dota a las máquinas de la capacidad de producir mensajes orales no grabados previamente como es el caso de los sistemas de respuesta oral. Tomando como entrada un texto, los sistemas de conversión texto-voz realizan el proceso de lectura de forma clara e inteligible y con una voz lo más natural y humana posible. La síntesis de voz conforma el interfaz oral de comunicación entre una máquina y el usuario de la misma.
Aquí puedes oir nuestro sistema de conversión texto-voz basado en la concatenación de difonemas.
Escribe la frase en castellano que desees enviar al conversor texto-voz, conecta el sistema de audio y envía la frase

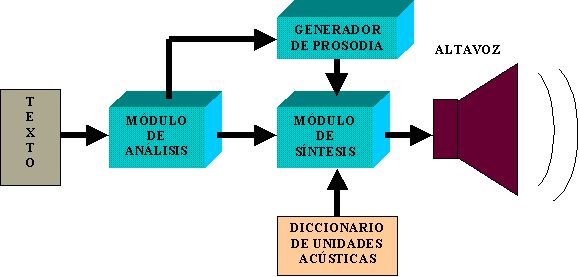
Para comprender los principios básicos sobre los que se asientan los sistemas de síntesis de voz hay que estudiar el proceso de generación de un mensaje oral desde el punto de vista acústico y lingüístico. Es necesario entender el comportamiento físico del aparato fonador del ser humano y como son procesados por el sistema auditivo humano para desarrollar un modelo matemático del mismo. A la vez hay que saber como extraer del texto, en base a su estructura lingüística, la información necesaria para controlar el modelo matemático y de este modo convertir el texto en voz. En el cuadro adjunto se presenta una clasificación de la señal de voz, en función de sus rasgos segmentales (sonidos elementales) y los rasgos prosódicos (características de enlace entre los aspectos lingüísticos y acústicos de la generación de voz).

En el aspecto lingüístico,
el primer problema que se encuentra un sistema de conversión texto-voz
es que debe inferir el contenido real de la representación escrita del
mensaje. Para ello se debería realizar un procesado lingüístico del texto
a partir de un análisis fonético-morfológico para derivar la pronunciación,
un análisis sintáctico para dar la estructura gramatical del texto y poder
inferir rasgos prosódicos, un análisis semántico para dar una representación
del significado del mensaje y un análisis pragmático para dar una relación
entre frases e ideas de la conversación global. Claramente, este procesado
lingüístico es muy ambicioso y los sistemas actuales simplemente realizan
un análisis fonético-morfológico y sintáctico para de este modo determinar
los rasgos segmentales y prosódicos de los sonidos que componen el mensaje
oral.
Un aspecto importante en la inteligibilidad y naturalidad de la señal
sintetizada son las reglas prosódicas, que aunque en cierta medida pueden
ser inferidas de la estructura sintáctica de la frase, la mejor forma
de generar una entonación adecuada a una frase es que la máquina entienda
lo que está diciendo.
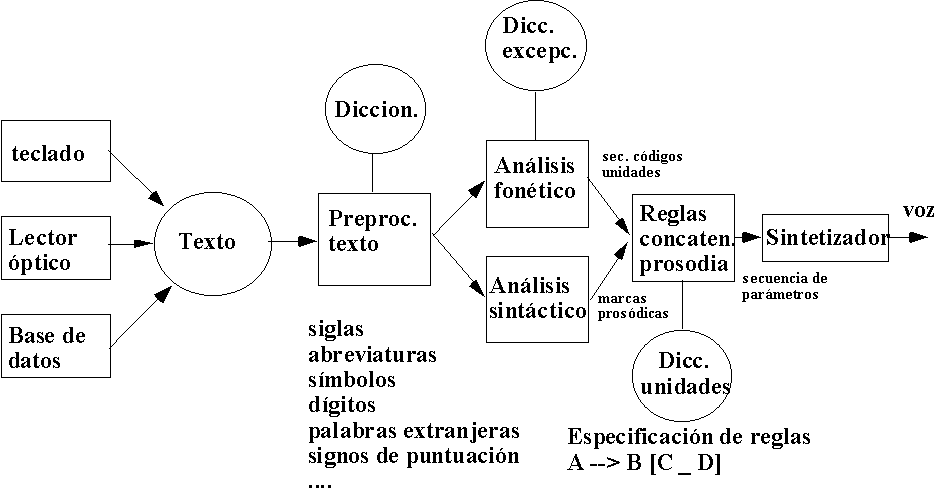
DIAGRAMA DE BLOQUES DETALLADO
DICCIONARIO DE UNIDADES ACÚSTICAS
La forma más sencilla de generar voz consiste simplemente en grabar la voz de una persona pronunciando las frases deseadas. Este sistema sólo es viable cuando el número de frases que es necesario sintetizar es pequeño. Por ejemplo, un número concreto de mensajes que se emiten en una estación de tren. En casos como éste, la calidad del sistema depende de la calidad de la grabación de las frases.
Sin embargo, en el caso de un sistema conversor texto-voz, se necesita un sistema que permita sintetizar cualquier texto que se introduzca por teclado. La solución consiste en dividir la voz en segmentos, los cuales van a constituir una base de sonidos con la que trabajará el módulo de síntesis.
Nuestro sistema conversor texto-voz emplea para producir voz el método de Síntesis Directa o Concatenativo, que consiste precisamente en concatenar uno tras otro todos los sonidos que constituyen el texto. Estos sonidos han sido previamente almacenados y constituyen la base de sonidos.
El primer problema que se plantea para crear una buena base de sonidos, consiste en decidir el tipo de unidades acústicas o segmentos fónicos adecuados para formar parte de dicha base. Existe un compromiso entre la calidad de voz conseguida y el tamaño de la base de datos que se necesita para almacenar los segmentos. Cuanto más pequeñas sean las unidades en que se descompone la voz, menor es la base de sonidos utilizada, pero la calidad de la voz también decrece.
Una solución a este problema es el empleo de difonemas, los cuales están compuestos por la porción final de un fonema y la inicial del fonema que le sigue. Como el corte está hecho en el centro del fonema, las transiciones entre ellos permanecen intactas. Para el caso del castellano, el número de difonemas necesario para constituir una base es de, al menos, 550. Para aumentar la calidad de la síntesis, se puede utilizar un número limitado de trifonemas para representar a sonidos en los que los tres fonemas se coarticulan a elevada velocidad (pla, ple, pli, plo, plu, tra, tre, ...)
Una forma de obtener la base de difonemas y trifonemas consiste en la grabación de logotomas. Los logotamos son palabras carentes de significado, compuestas por tres sílabas, que permiten que el segmento a tratar esté aislado sin coarticular con los sonidos anterior y posterior. De las tres sílabas que componen el logotoma nos interesa la sílaba central, que es donde se encuentra el segmento a extraer. Su estructura general es la siguiente:
|
PRIMERA
SÍLABA
|
SONIDO
EXPLOSIVO
|
SONIDO
QUE BUSCAMOS
|
SONIDO
EXPLOSIVO
|
ÚLTIMA
SÍLABA
|
Por ejemplo:
Opoat´e: o-p-oa-t-´e se extrae el difonema oa
Ombrité: o-m-bri-t-´e se extrae el trifonema bri
Existen algunas excepciones,
por ejemplo logotomas en los que no hay sonido explosivo final:
Etip´o: e-t-ip-´o
Debido a las numerosas excepciones, es necesario realizar un estudio del
logotoma apropiado para cada difonema-trifonema.
EL MÓDULO DE ANÁLISIS LINGÜÍSTICO
El módulo de análisis lingüístico del texto lleva a cabo dos funciones fundamentales:
1. transforma la representación ortográfica del mismo en una representación fonética, es decir, determina la sucesión de difonemas y trifonemas que lo componen.
2. extrae del texto la información prosódica del mismo. Esta información se llevará al generador de prosodia, el cual generará la plantilla de prosodia adecuada que permita al sintetizador generar voz con una buena entonación.
Lógicamente, este análisis lingüístico del texto es diferente para cada idioma, teniendo que adaptarse a las características propias de cada uno. Hay que tener en cuenta que tanto la base de fonemas como las características prosódicas son distintas para cada idioma. El texto que se desea sintetizar ha de ser analizado conforme a sus propiedades sintácticas, semánticas y contextuales para producir los parámetros adecuados.
En la siguiente figura se muestra el diagrama de bloques del módulo de análisis lingüístico de nuestro conversor texto-voz.

El bloque de preprocesado del texto realiza las funciones de tratamiento de abreviaturas, números, horas, fechas, signos de puntuación, etc.
Para silabificar el texto, éste se va tomando palabra a palabra (el texto pasado por el módulo de preprocesado) y se aplican una serie de reglas lingüísticas basadas en las posiciones relativas de las vocales y consonantes.
El objetivo del módulo de acentuación es obtener una representación del texto que incluya la información de las sílabas acentuadas en cada palabra. En castellano, sólo las vocales pueden ser acentuadas, por lo que se dispondrá de una doble representación de las vocales: sin acento {"a", "e", "i", "o", "u"} y con acento {"´a", "´e", "´i", "´o", "´u"}.
En el bloque
de transcripción fonética se pasa de la representación ortográfica
del texto a una cadena de fonemas. Para ello, se analiza letra a letra
en cada palabra (distinguiendo la sílaba en la que aparece). Se entiende
como "letra", una secuencia de caracteres que se definieron como vocales
o consonantes en una apartado anterior. Por lo tanto, pueden aparecer
"letras" compuestas por varios caracteres.
Los listados de fonemas utilizados, son los siguientes:
static char *Fonemas[]={"a", "e", "i", "o", "u", " ´a", " ´e", " ´i",
" ´o", " ´u", "j", "w", "b", "B", "d", "D", "g", "G", "p", "t", "k", "T",
"S", "f", "s", "z", "x", "m", "n", "J", "N", "l", "L", "r", "R", "jj"}
static char *FonVoc[]={ "a", "e", "i", "o", "u", " ´a", " ´e", " ´i",
" ´o", " ´u", "j", "w"}
Este bloque permite hacer la transcripción fonética del texto. Si se introduce el texto obtenido a la salida del bloque de acentuación:
´es-to ´es ´un e-j´em-plo de c´o-mo va-r´i-a la re-pre-sen-ta-ci´on de ´un t´exto, al pa-s´ar-lo por los dis-t´in-tos bl´o-ques del m´o-du-lo de a-n´a-li-sis.
después de este bloque obtendremos:
´es-to ´es ´un e-x´em-plo De k´o-mo Ba-r´i-a la Re-pre-sen-ta-Tj´on de ´un t´es-to, al pa-s´ar-lo por loz Dis-t´in-toz Bl´o-kez Del m´o-Du-lo De a-n´a-li-sis.
En el bloque de análisis de la frase se estrae el típo de frase para utilizar el patrón entonativo adecuado. En el generador de prosodia se han implementado cuatro patrones melódicos diferentes, para cuatro tipos de frases distintas. Por lo tanto, necesitamos saber a qué tipo de frase pertenece cada difonema/trifonema para poder aplicar el patrón melódico correspondiente. La clasificación de cada frase del texto se realiza en función del signo de puntuación o terminación de dicha frase. A continuación se detalla la clasificación realizada:
|
TIPO
DE FRASE
|
TERMINACIÓN
|
|
Enunciativa
terminada
|
".", "...", ")", "*", "#" |
|
Enunciativa
inacabada
|
",",
";", ":", "("
|
|
Interrogativa
|
"?"
|
|
Exclamativa
|
"!"
|
Este bloque realiza también la clasificación del difonema/trifonema para la aplicación posterior de un modelo de duración vocálica. Se clasifica el difonema/trifonema en:
vocalico/no vocalico ..... si lleva o no una vocal
acentuado/no acentuado
sílaba abierta /sílaba cerrada
posición prepausal/ no prepausal
Si se introduce el texto obtenido a la salida del bloque de transcripción fonética:
´es-to ´es ´un e-x´em-plo De k´o-mo Ba-r´i-a la Re-pre-sen-ta-Tj´on de ´un t´es-to, al pa-s´ar-lo por loz Dis-t´in-toz Bl´o-kez Del m´o-Du-lo De a-n´a-li-sis.
al terminar su tratamiento en el módulo de análisis lingüístico, la secuencia de difonemas y trifonemas que componen el texto tendrá la siguiente representación:
e es st to es su un ne ex xe em mp plo oD De ek ko om mo oB Ba ar ri ia al la aR Re ep pre es se en nt ta aT Tj jo on nd de eu un nt te es st to o_ // a al lp pa as sa ar rl lo op po or rl lo oz zD Di is st ti in nt to oz zB Blo ok ke ez zD De el lm mo oD Du ul lo oD De ea an na al li is si s_ //
MÓDULO DE SÍNTESIS
EN CONSTRUCCIÓN
GENERADOR DE PROSODIA
La naturalidad al hablar se consigue con una buena entonación, la cual puede ser incluso necesaria en algunos casos para la inteligibilidad del mensaje. Por ejemplo, la frase "Juan dijo Pedro es un mentiroso", se puede pronunciar de forma diferente, de manera que se podría interpretar de cualquiera de los siguientes modos: "Juan dijo: Pedro es un mentiroso", o "Juan, dijo Pedro, es un mentiroso". En este caso, la entonación contribuye a que cambie el significado del mensaje.
La entonación se considera uno de los principales responsables de la calidad de un conversor texto-voz.
La entonación es, ante todo, un fenómeno lingüístico relacionado con la sensación perceptiva que produce la variación a lo largo de todo un enunciado de tres parámetros físicos:
frecuencia fundamental (en adelante la denominaremos F0)
duración
amplitud
proporcionando esta variación, al receptor, información de distintos tipos. Estas variaciones se dan en unidades mayores que la palabra, normalmente sintagmas o frases, que son las unidades lingüísticas contenidas en los grupos fónicos. Un estudio de la entonación implica, por tanto, estudiar las variaciones de los parámetros entonativos a lo largo de todo el grupo.
La entonación es un fenómeno que relaciona tres niveles diferentes:
-
Plano físico (o acústico): en este sentido, es el resultado de la variación temporal de una serie de parámetros físicos. Se considera que los tres parámetros antes mencionados, son los responsables de la entonación. Éstos,también intervienen en otros fenómenos, como el ritmo o el acento, lo que hará que en ocasiones sea difícil atribuir la variación de un parámetro determinado a un fenómeno u otro. ·
-
Plano perceptivo: el oído humano actúa como un filtro que, en cierta medida, transforma la señal sonora que le llega, desechando algunas de las variaciones de esos parámetros físico tratados en el apartado anterior. ·
-
Plano semántico-funcional: el oyente extrae de las variaciones de los parámetros antes mencionados, diversas informaciones de tipo lingüístico, o incluso extralingüístico.
Además, transmite los siguientes tipos de información:
- Información de tipo lingüístico, referente al mensaje, que es generalmente información sintáctica. En primer lugar, permite delimitar las diferentes frases que componen el mensaje. También aporta información sobre el tipo de oración de que se trata. Igualmente, permite distinguir entre enunciados no finales, situados al principio o en medio de una oración, y los resultados al final de las mismas.
- Información sociolingüística, acerca de la procedencia geográfica y social del hablante.
- Información expresiva, acerca del estado de ánimo del hablante.
Según un estudio de Jassem y Demenko (JASSE, W.,-DEMENKO, G., "Extracting Linguistic Information from F0 traces" Ed. Johns-Levis,C., Intonation in Discourse, Londres, Croom Helm, 1986.) existen catorce factores diferentes que pueden determinar las variaciones de los parámetros que influyen en la entonación. Estos factores son los siguientes:
- Condiciones dependientes de la actitud del hablante, situaciones y del discurso.
- Situación del acento temático.
- Realización del acento léxico o gramatical.
- Longitud de la curva, condicionada segmental o léxicamente.
- Variación alotónica libre.
- Efectos de estados emocionales.
- Rasgos fisiológicos personales del hablante.
- Rasgos patológicos de la voz.
- Cambios momentáneos en el tono medio (confidencias, frases parentéticas...).
- Tempo personal de elocución.
- Cambios momentáneos del tempo.
- Efectos de los rasgos segmentales.
- Irregularidades no patológicas en la fonación.
- Estilo.
De todos estos factores, sólo algunos transmiten información relevante para el receptor.
Los patrones melódicos.
Vamos a considerar melodía y entonación como dos fenómenos diferentes, aunque relacionados entre sí. Definimos melodía como el fenómeno que se relaciona con la curva de frecuencia fundamental o curva melódica de un grupo fónico (considerando grupo fónico como el enunciado comprendido entre dos pausas del discurso).
Ya se ha comentado que la información que transmite la entonación se reparte a lo largo de unidades superiores a la palabra, normalmente sintagmas o frases, que son las unidades lingüísticas contenidas en los grupos fónicos.
Se asocia a cada tipo de información una forma típica de curva o patrón melódico. Los patrones melódicos representan esquemáticamente la forma de las curvas de F0, y podrían identificarse con las representaciones estilizadas obtenidas tras la eliminación de las variaciones irrelevantes. La curva melódica se convierte, por lo tanto, en una unidad básica para el estudio de la entonación.
Se pueden distinguir dos grandes clases de curvas melódicas, en función del grupo fónico al que pertenezcan. Los grupos fónicos son terminales o no terminales según la posición en que aparezcan dentro de la oración: ·
- Los grupos terminales son los que aparecen al final de una oración. Contienen básicamente información sobre el tipo de oración, lo que se denomina modalidad oracional.
- Los grupos no terminales son los que aparecen, en oraciones con más de un grupo fónico, en posición no final dentro de las mismas. La información que contienen se refiere al tipo de frase subordinada.
Para el castellano, Alcina y Blecua en su gramática ( REAL ACADEMIA ESPAÑOLA, "Esbozo de una nueva gramática de la lengua española" Ed. Espasa-Calpe, Madrid, 1982.) , distinguen tres partes dentro de una curva melódica:
- La rama inicial de la curva, "formada por las sílabas átonas que llegan hasta el primer acento fuerte".
- El cuerpo, que "está formado por el conjunto de sílabas que comprenden la sílaba fuerte inicial hasta la sílaba inmediatamente anterior al último acento fuerte".
- La rama final, "que está integrada por la última sílaba fuerte y las siguientes débiles, en el caso de que las haya".
En cuanto a la cuestión de los elementos que contienen más información dentro de una curva melódica, hay varias teorías; la mayoría de ellas coinciden en señalar que la información lingüística aparece en la rama final. Para las informaciones de tipo sociolingüístico y expresivo no hay acuerdo en las diferentes teorías.
Tipos de patrones melódicos del español.
Hay varios estudios sobre los patrones melódicos del español, como son los realizados por la Real Academia de la Lengua , Quilis y Fernández (QUILIS, A.,-FERNÁNDEZ, J.A., "Curso de fonética y fonología españolas" Madrid, Consejo Superior de Investigaciones Científicas, Instituto "Miguel de Cervantes", 1979), Quilis (QUILIS, A., "Fonética acústica de la lengua española" Colección Biblioteca románica hispánica III: Manuales 49 Ed. Gredos, Madrid 1981) , Canellada y Kuhlmann (CANELLADA, MARIA JOSÉ,-KUHLMANN, JOHN, "Pronunciación del español: lengua hablada y literaria" Ed. Castalia, Madrid, 1987) , y el más completo, realizado por Navarro Tomás (NAVARRO TOMAS, T., "Manual de entonación española" Ed. Guadarrama, Madrid, 1974), que clasifica los patrones melódicos en cuatro grandes grupos:
- Patrones enunciativos:
son los que aparecen en las oraciones enunciativas, es decir, aquéllas
que simplemente expresan "la conformidad o disconformidad lógica del
sujeto con el predicado", tal como ocurre en:
Son las nueve y media. - Patrones interrogativos:
dentro de éstos se puede hacer otra clasificación:
2.1. Patrones de las interrogativas absolutas: este tipo de interrogaciones son las que han de tener "sí" o "no", obligatoriamente, como respuesta.
¿Vendrás a mi casa hoy?
2.2. Patrones de las interrogativas pronominales: aquellas preguntas que contienen una partícula interrogativa, y cuya respuesta tiene que ser diferente de "sí" o "no".
¿Cómo te llamas?
2.3. Patrones de las interrogativas relativas: todas las interrogaciones que buscan confirmar algo que no se sabe con certeza, pero se intuye de alguna manera.
¿Verdad que no? - Patrones exclamativos:
son los que aparecen en aquellas oraciones con un contenido expresivo
o emocional. Podrían señalarse tantos subgrupos de esta clase como emociones
o estados afectivos puedan ser expresados por un hablante. Navarro (
pág. 156) menciona bastantes tipos: alegría, tristeza, orgullo, miedo,
cariño, desdén, odio,...
¡Qué bonito! - Patrones volitivos:
son los que aparecen en oraciones "que indican exhortación, mandato
o prohibición". Navarro distingue tres tipos:
4.1. Patrones de mandato: propios de oraciones imperativas.
¡Cállate ahora mismo!
4.2. Patrones de recomendación: en oraciones que contienen mandatos atenuados, sugerencias o recomendaciones.
¿Tendría la bondad de entregarle esta carta?
4.3. Patrones de deseo, en oraciones que expresan deseos del emisor.
Me gustaría que vinieras a cenar.